

Chameleon at its core is a database with a flexible database schema which can be used to contain almost any type of data. Through our hybrid design using the best of relational and key/value pair design, it becomes an ideal warehouse for data. And with a powerful web interface, users can organize data in unlimited ways.
What is less known about Chameleon are some of the more technical aspects, namely its capability as an open platform for developers and users. Here are some of the highlights:
-
- Chameleon API for writing graphics apps using Chameleon or external data
- Open database design allowing 3rd parties to add parsers and other data related services
- SDK for tight integration to Chameleon’s ticker and branding resources
- BLADE – RESTful api providing endpoints to all containers in multiple formats
- Community support – sharing data between instances of Chameleon
- Dynamic Tags – foundation for extending existing data types
- Custom data type when there isn’t a fit with one of the other standard data types
- Query data type for creating dynamic playlists using any and all Chameleon data
- Scripting support for html5 Designer
- OEM Support and Interface Skinning/Feature Hiding
Chameleon.api
All the rendering for our html5 graphics is done on the client side (JavaScript on a client’s browser). But there’s a pipe of data between an application we call the Chameleon Web Server to tell JavaScript what project, scene and data mappings to use for each render.
The Chameleon.api is an interface to the Chameleon Web Server to allow it to do more than just tickers. This interface listens for commands to show a scene with a set of key/value pairs to map to fields in the scene. The api is a simple interface to load projects, set scenes online or offline, update an existing scene and a callback to signal the end of a render.
The Chameleon.api is available in nuget to integrate into 3rd party applications. Those applications might be scorebugs, sequencers or any custom requirement for rendering graphics. In fact, Bannister Lake uses this api for some of their own applications like the Branding and Elections Player.
We encourage developers to use the Chameleon.api to create the next great graphics application.
Open Database
Chameleon uses MySQL as its database system. It is an open-source relational database management system. It is a free and open-source software under the terms of the GNU General Public License and is also available under a variety of proprietary licenses. There are derivatives to MySQL such as MariaDB and others.
We learned early on that Bannister Lake could never provide all the data resources to populate our database. Language limitations limit our capability of writing resources for datafeeds of character sets like Kanji. We certainly can contain that data in Chameleon but without language experts, we have no way of interpreting the data.
For this reason, our goal was to open up the Chameleon database to internal and 3rd party developers to create parsers or any other data script for our Chameleon customers. For that purpose, we have made access to the Chameleon database open by providing common MySQL credentials to allow access to MySQL Workbench and MySQL connection tools for any type of software development. We even provide sample source code to parsers.
SDK
All of Chameleon’s data/containers can be used in a loose fashion through BLADE. It’s a powerful way to support all platforms including web widgets, character generators and digital signage. However, Chameleon allows for tighter integration of graphics through its SDK. This allows for tickers to use rundowns and branding assets.
Tight integration also requires publishing information about graphics to the database. This provides templates for generating bugs or snipes. It also provides the magic to include data containers for a rundown’s zones.
The SDK itself is on the playout side for creating players that can use all these database resources for tickers and branding. For tickers, it allows mapping containers to graphic zones in a ticker making it as simple as dragging a data container into a rundown. The SDK covers all the work behind the scenes to make this all work.
For example, here is a rundown for a zone in a show (our term for a group of zones)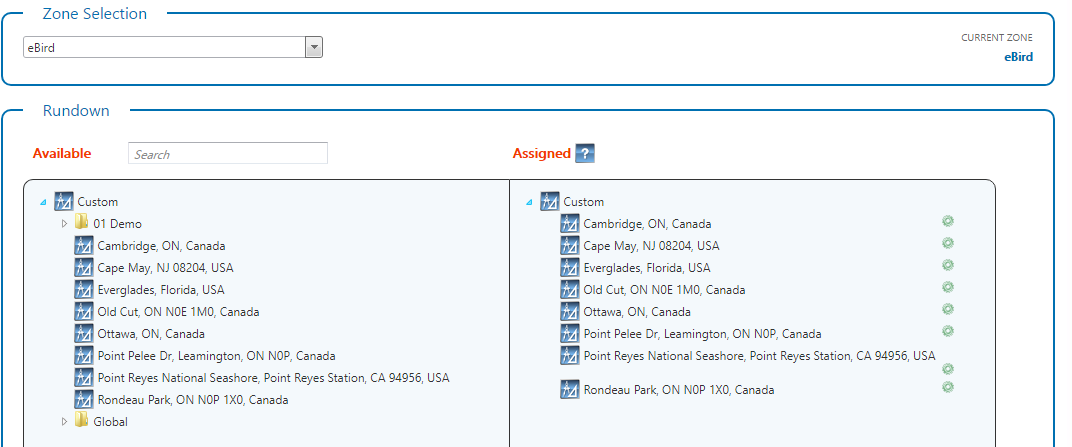
Using the information in the database when graphics are published, rundowns know what types of containers it can support. This tight integration of graphics also extends to branding assets. Here’s an asset defined to provide a countdown clock bug to Christmas:
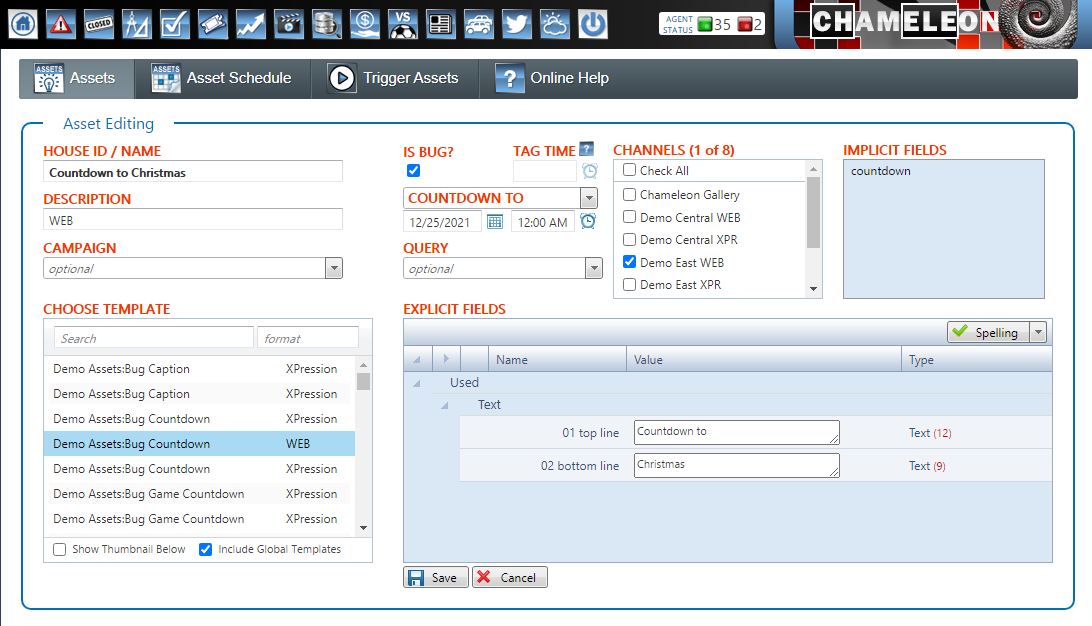
When a platform supports these graphics-based resources in the Chameleon database, we call the platform tightly coupled. Once tightly coupled, a platform has some magic behind it where tickers and branding are all defined in Flow, Chameleon’s web interface.
The interface to the SDK for providing tightly coupled support is a series of methods that are not unlike the Chameleon.api where it supports information about bringing scenes online or offline and updating. It’s even possible to have an SDK implementation support Chameleon.api to provide additional 3rd party development support.
BLADE
Chameleon has an endless supply of data containers. Those containers might be a broadcast channel’s program schedule, world news, league scores, stock index quotes or weather for a group of cities. Each container has an endpoint for acquiring the data from a url to be used with any platform whether it’s a ticker (broadcast, digital signage, streaming,…), website, branding or character generator.
BLADE (Bannister Lake Active Data Exchange) is a RESTful api to all that data. There is a url to pull any Chameleon container. Not only that, Flow provides a page to discover the urls. For example, if we wanted to find the json url for getting the Dow Jones 30 components, Flow’s BLADE discovery page makes it easy. No docs to read. Just pick what you want: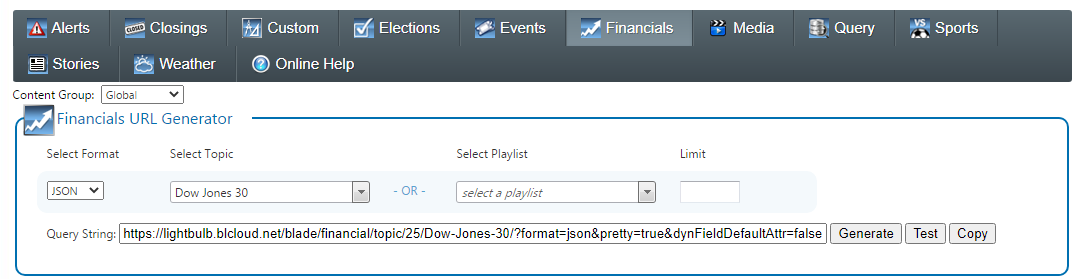
The url discovered here is an active and live resource located on one of our cloud instances and formatted in json. Go ahead and give it a try:
Originally, BL created a central location to store useful information like sports scores or weather forecasts. This was intended as a data resource for our customers. We also opened it up so that data providers could login to an instance of Chameleon and edit their own data for broadcasting purposes.
But we went further with this idea. What we came up with is a way to share data between any Chameleon instance. Basically, Community Support provides a way of syncing a container with a container from another Chameleon instance (another database) or even between content groups of the same Chameleon instance. We call these container to container syncs maps.
In Flow, users can setup maps by defining the Chameleon instance source and then mapping a source container to a destination container: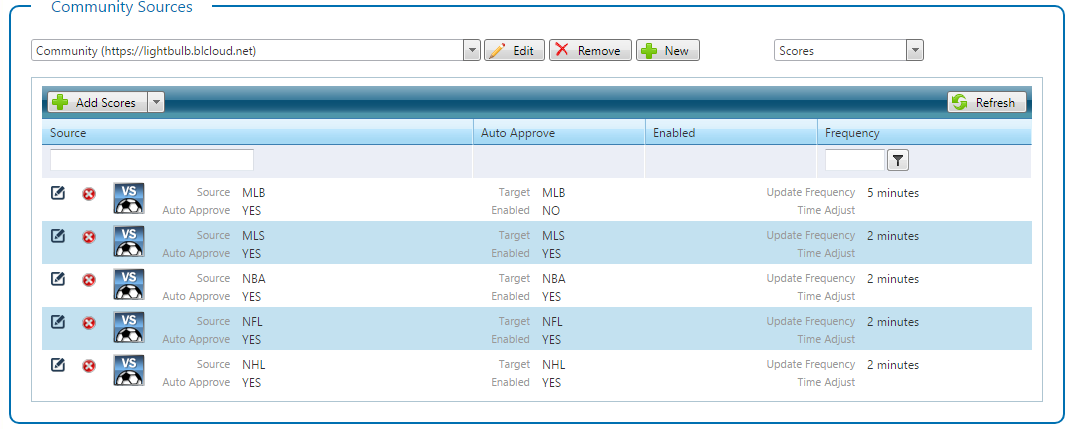
In this example, we’re mapping the Chameleon instance located at https://lightbulb.blcloud.net all the sport scores for leagues MLB, MLS, NBA, NFL and NHL. We support mapping of most Chameleon containers, even query source containers (mapped to Custom).
Dynamic Tags (aka Dynamic Fields)
Early on in the design of Chameleon, we found the need to extend existing data types with additional fields. For example, each sport has unique data beyond team names, scores and status. While baseball might need information on who is up to bat, the count, team errors and so much more, a sport like hockey might need shots on goal, hits, penalty/power play information. There are 2 ways to approach this problem. Either add new fields to a relational data table (forever) or attach additional data to a core data type. We chose the 2nd method. All of the Chameleon data types have support for extending data by attaching dynamic tags to records. These dynamic tags can be text, numbers, dates, boolean, json or media. We even went all in on this idea by having a data type we call Custom which is essentially just dynamic tags.
For example, here’s a simple dynamic tag providing a logo for episodes of Bonanza: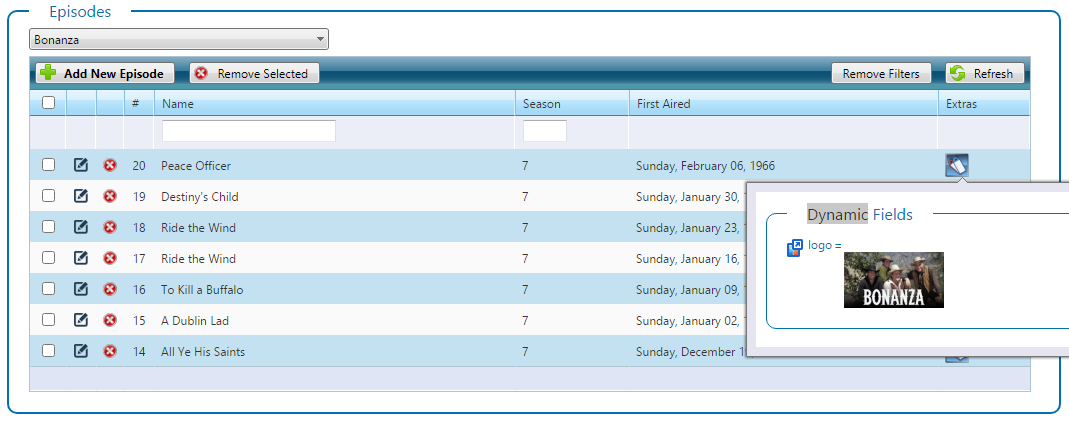
And here are dynamic tags for an NHL player:
Note that we are working on a new data type for dynamic tags: set. Basically, a set is a set of dynamic tags. This is a way for any dynamic tag to reference a set of dynamic tags providing full hierarchy of data. This could be used to store season or game information for players or teams. It could also be used to store different language versions for a story.
Custom Data Type
Not all data fits into standard Chameleon data types such as story, weather or finance. That’s where the Custom data type comes in. It is essentially key/value pairs attached to records. Chameleon calls these key/value pairs dynamic tags or dynamic fields. Although all the other data types have key/value pair support, the Custom data type is exclusively key/value pairs. Any 2 dimensional data is a good candidate for using the Custom data type. For example, a spreadsheet is a good example of what is a good fit for Custom where each column is a field and each row are the values to a record.
A good example of the use of Custom is containing COVID-19 data. For example, here is Canadian COVID-19 data organized by province: Here we’re showing some of the fields for the province of Quebec.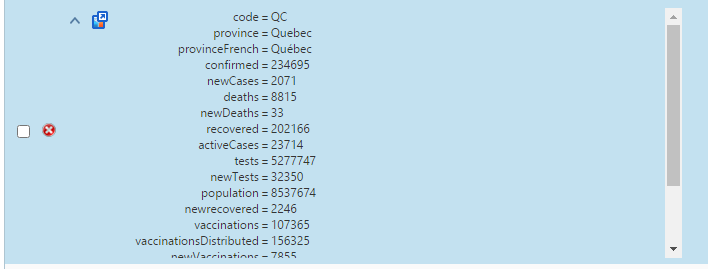
Another example is organizing medal counts for events like the Winter Olympics: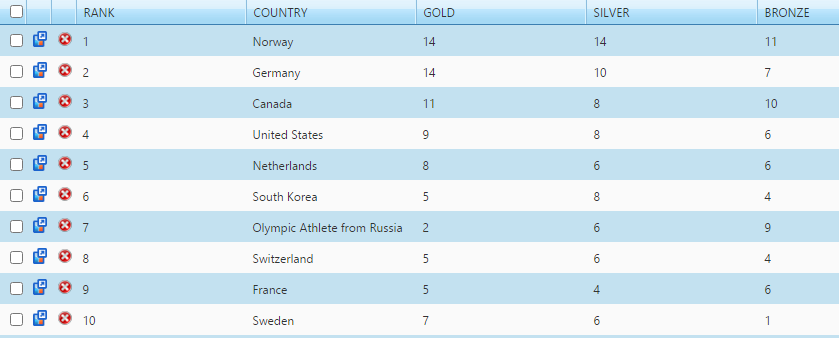
Like all dynamic tags in Chameleon, key/value pairs can be strings, dates, numbers, booleans or media. Custom data is organized in topics and is just another container to Chameleon where it can be used like any other container.
Query Data Type
Query is Chameleon’s method for creating dynamic playlists and to format data in a precise way. For example, if we had all the Dow Jones components in a Financial container ordered ascending by symbol: 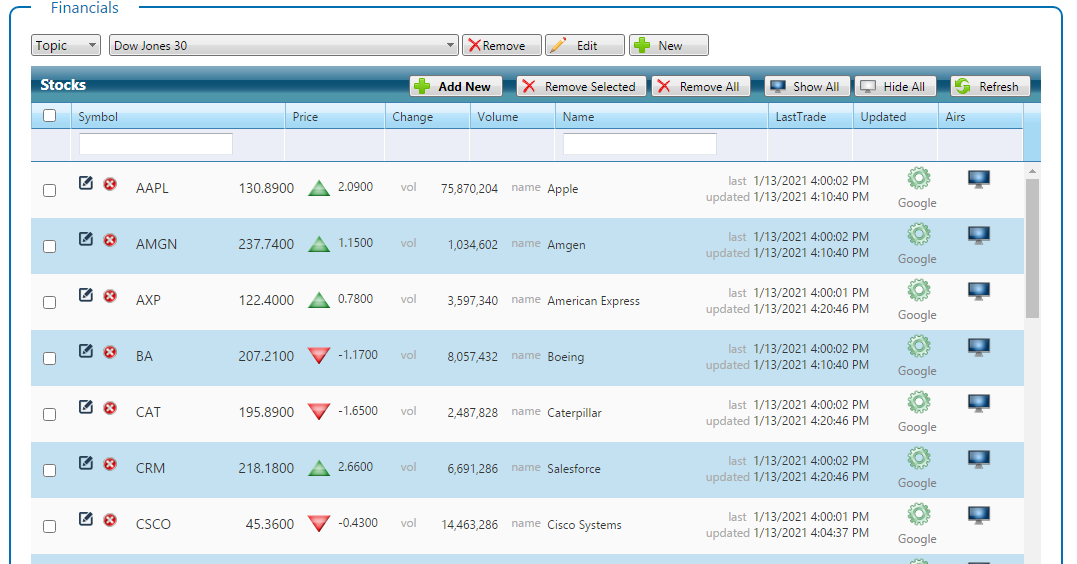
What if we wanted the data sorted descending by volume? One could create a playlist and manually order by volume but when the markets are open, the data is highly dynamic. That’s where Query comes in. It can create dynamic playlists. And these playlists are treated like any other container in Chameleon with the difference being the query behind it gets executed whenever utilizing the container.
Query is based on writing SQL SELECT statements. These statements are what get executed on the container. Any data in the database is fair game for query. Here’s an example of the SELECT statement behind a query for getting the top 10 volume leaders for the Dow Jones 30 components: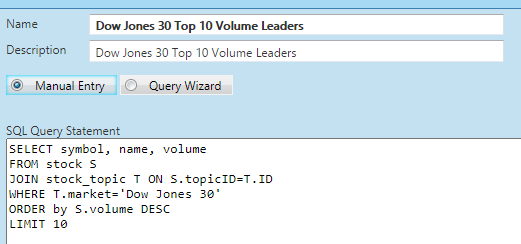
The above query gives us: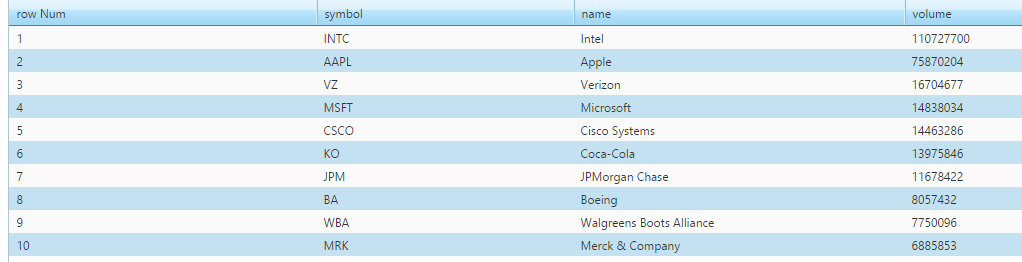
Designer Scripting
Most character generators or graphics environments have some form of scripting support. Chameleon’s web renderer is no different in that respect. It allows writing scripts to accomplish dynamic tasks. For example, here’s a script for a scene that shows sports scores. It will mark the team with the colour red if the team is leading or has won: 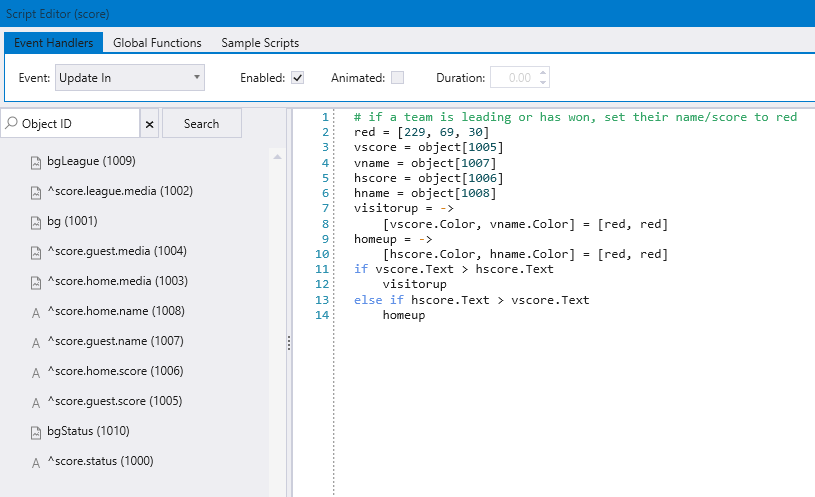
Designer uses CoffeeScript as its scripting language which gets translated to JavaScript at render.
OEM Support and Interface Skinning/Feature Hiding
Chameleon’s most visible interface is Flow. Flow is the web interface which provides access to the world of Chameleon; not just the data but the operational aspects of data like triggering graphics. From the beginning, Flow provided support for skinning Flow. For example, each election, we’d provide a different skin for our election users. We also provide support for hiding features so users aren’t bombarded with things they don’t need or want.
Flow can easily hide content by turning on and off features. If an instance of Chameleon is used for only sharing/working with certain data types, it’s easy to hide features. For example, here is what is available for our Community instance:
While an instance like our Chameleon cloud instance provides more functionality for playing out graphics:
It’s also possible to skin Flow for any purpose whether it’s for OEM partners, internal customer support or distinguishing between instances. Here are a few examples of Flow headers:![]()
![]()
![]()
In the last example, it shows an example of Chameleon as an OEM product for Ross Video. We are seeking interest from new OEM partners who wish to integrate Chameleon into their own product eco-system. Everyone needs good data so Chameleon is an excellent fit for many products.