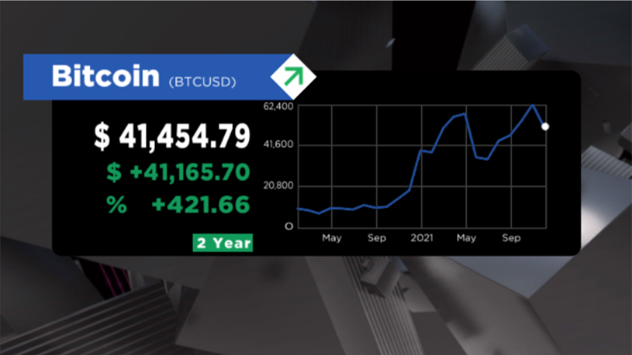
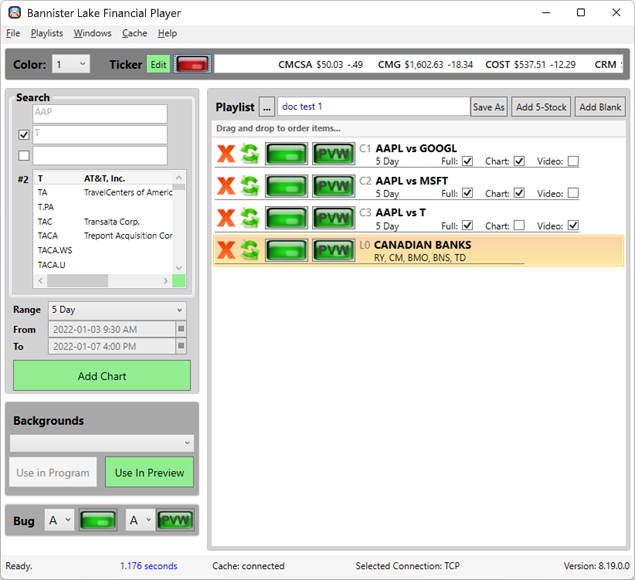
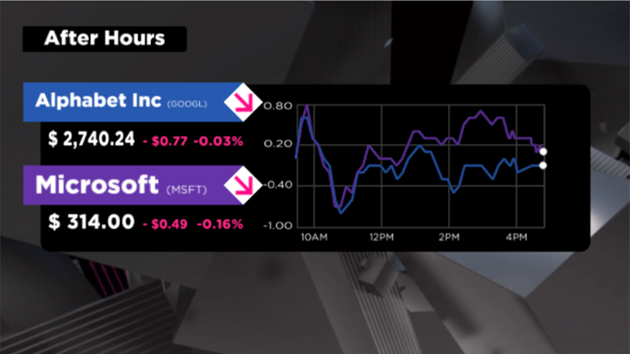
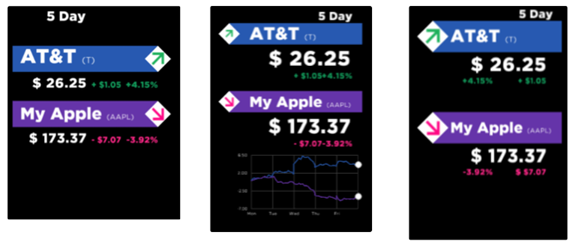
This year’s US Open Tennis Tournament at Flushing Meadows, NY is being driven by Bannister Lake’s cloud-based Chameleon, managing and visualizing real-time results for all the events.
Chameleon is managing thousands of tennis datasets from Sports Media Technologies IBM solutions, moderating and distributing matches and practice schedules, match results, social media, news, weather and more for the in-venue displays.
Bannister Lake working alongside Van Wagner Sports and Entertainment is delivering live updates and tournament information to digital displays throughout the facility.
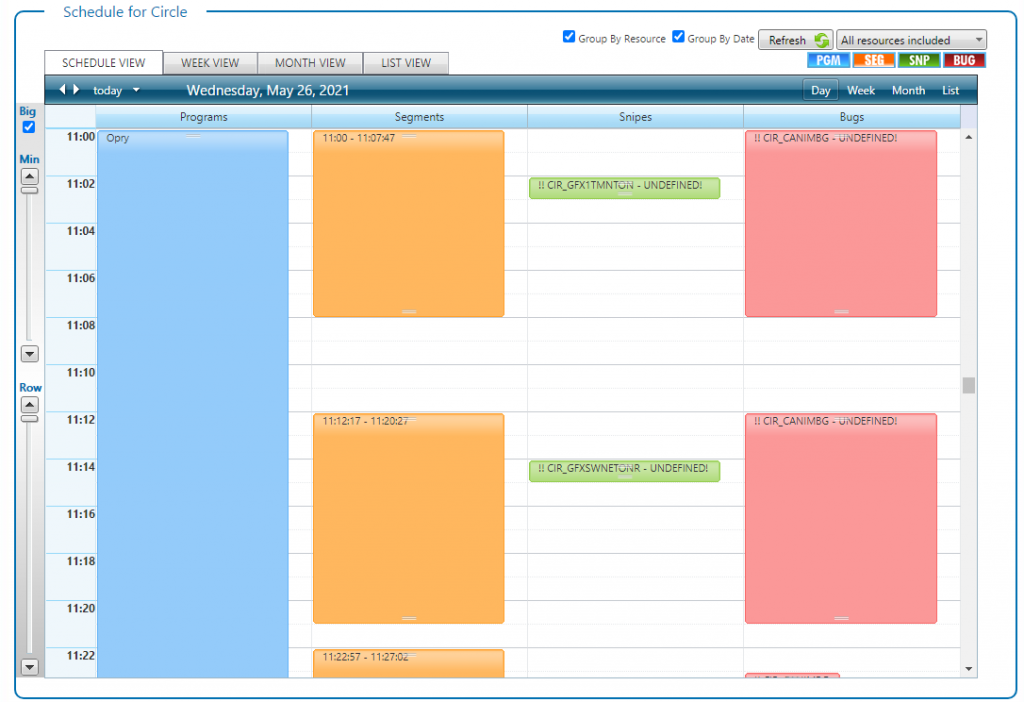
“It’s been one of our largest and most complex projects”, says Alain Savoie, Bannister Lake’s Creative Director. “There are 864 players competing with 900 matches to be played over the 2-week period. Every single game needs the ability to be called up on the fly and include match data and player data.”
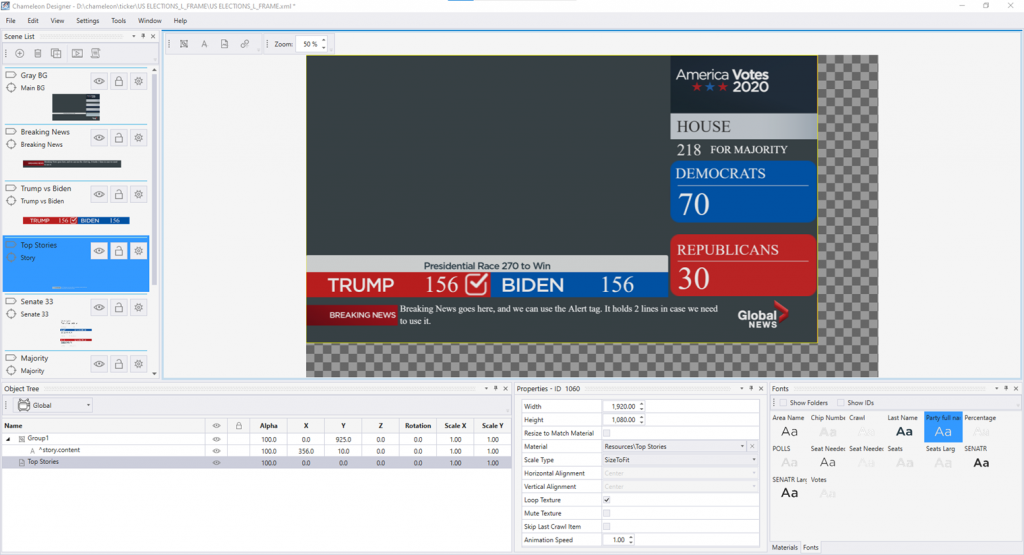
In addition to parsing and managing data, Chameleon is providing the event’s ticker solution. In all, 7 different ticker feeds are being generated and feeding various screens around the grounds. Signage graphics were generated from 3 Ross Video XPression systems outputting to 9 channels displaying sponsors and logo loops appearing at specific times throughout the day.
In addition to the main grounds there are another 10 XPression systems being used for traditional CGs in the Grandstand, Armstrong and Ashe Stadiums, as well as the Ashe Courtside displays powered by Ross Video’s XPression Tessera, controlled through Ross Video DashBoard. Chameleon’s tight integration with Ross Video products assures operational efficiencies and seamless performance.
Bannister Lake’s Chameleon with its powerful data engine remains the sports industry’s best choice for complex mission-critical data visualization tasks. For more information about Chameleon, visit our website or contact us at info@bannisterlake.com